
《王者荣耀》上线多年,大家都知道它的普及程度已经可以称为一款“国民级游戏”。上至万元高端机,下到百元老人机,我们都可以看到它的身影。

但一个有趣的现象是,这么多年来,《王者荣耀》一直在提升美术资产品质,却依然可以在低端机,甚至安卓手表运行。同时,它也没有受到繁复的资源适配工作影响,并总是保持着稳定的更新频率。这是为什么?
在8月14日由腾讯游戏学堂举办的第六届腾讯游戏开发者大会(Tencent Game Developers Conference ,即 TGDC)上,腾讯互娱天美L1工作室渲染技术专业指导夏飞,带来了《王者荣耀》可微渲染的相关技术分享,介绍了一套基于可微渲染的智能资产辅助生产系统。
下面是葡萄君整理的内容分享:
大家好,我是来自于腾讯IEG天美L1工作室的夏飞。我分享的主题是《Mythal——基于可微渲染的智能资产辅助生产系统》。
这次分享首先我会介绍一下什么是可微渲染,以及它能解决什么问题;然后会分享下可微渲染管线的实现原理,以及可微渲染在《王者荣耀》项目中的实际应用;最后我会展望下可微渲染将来的应用前景。
大家肯定有疑惑,那到底什么是可微渲染呢?它和普通的渲染有什么区别和联系呢?我们为什么需要可微渲染呢?下面我将一一解答大家的疑惑。
01 什么是可微渲染?
为了理解为什么需要可微渲染技术,我们先看看在开发“《王者荣耀》“的过程中所碰到的难题。
《王者荣耀》需要覆盖极为宽广的机型范围,下到只支持Gles2.0的百元老人机,上到万元高端机。这就对渲染的伸缩性提出了很高的要求,一是高端机上需要提供给玩家最好的效果,充分发挥出高端机的机能。二是低端机上也需要能流畅运行我们的游戏,让尽量多的玩家能享受《王者荣耀》带来的快乐。
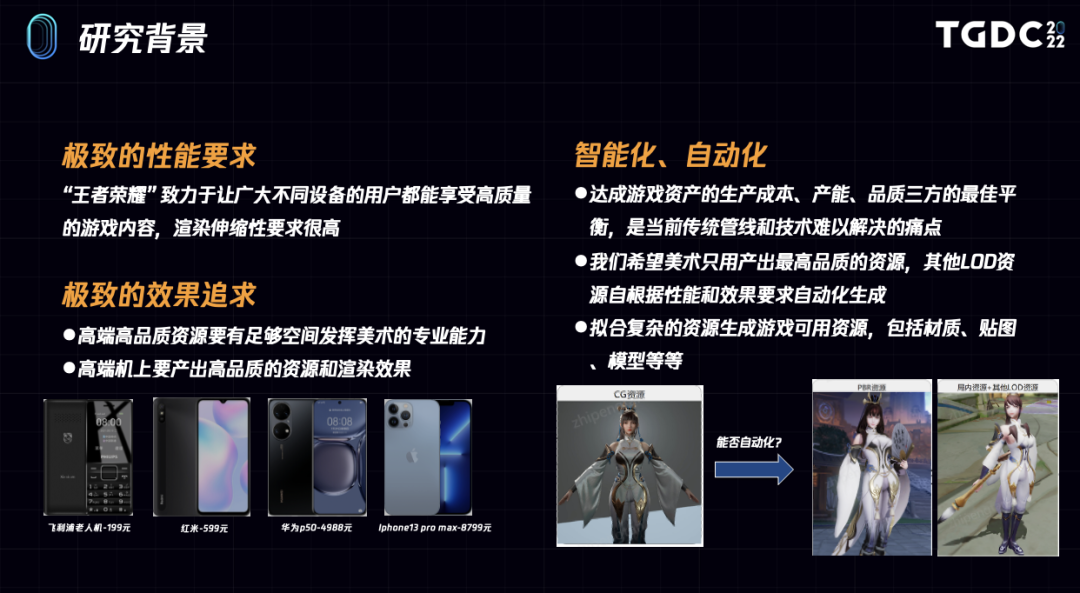
宽广的机型覆盖范围也对资产生产管线提出了极高的要求,传统的管线和技术需要相关制作人员同时制作和维护多套游戏资源,极难达成生产成本、产能、品质三方的最佳平衡。我们希望让美术同学发挥所长,只用产出最高品质的资源,而其他LOD资源能根据性能预算和效果要求自动化生成出来。
这是两个《王者荣耀》所需支持的设备例子,其中一个是安卓手表,另一个是安卓小手机,在这些设备上都需要流畅地运行游戏,这其实是一个很困难的问题。
具体来说我们需要针对最高渲染结果自动化拟合出Lod游戏资产,包括材质、贴图、模型等等。在多年的摸索中,针对各个具体问题我们实现过多种方案和算法,有线性回归、最小二乘法、模拟退火、遗传算法等等经典算法。

但是这些算法有着各种缺点,无法满足项目的要求,下面我们通过几个例子来说明这些传统方案的不足。

左图是我们用传统引擎技术在王者峡谷中通过固定视角烘焙渲染结果来做材质的简化,右图是局外展示角色的烘焙简化,可以看到它们的烘焙效果都不太好。我们之所以要做这么一个烘焙简化,是因为各种不同的机型性能要求相差很大。有些机型上只能跑非常简单的渲染,但是我们想做到最好的品质。上面的问题在于:
缺乏误差量化的手段、无法评估是否为当前性能目标下的最优效果,失去了PBR中至关重要的金属材质表现力。另外UV1图像空间不连续导致的接缝问题,是传统渲染手段不太好解决的问题。最后这些方案还缺乏鲁棒性、算法一般不具备通用性,效果与特定场景强相关,需要美术专家后期较多的修饰。
这是另外两个例子:
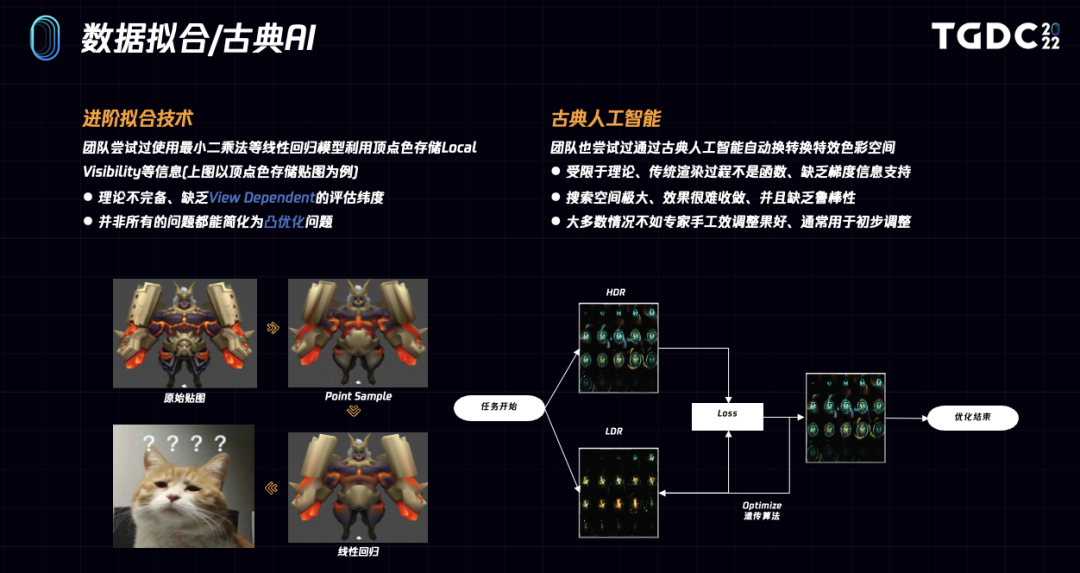
左图是我们在极致优化效率的时候,会把贴图级数据拟合到顶点色上面,比如diffuse、渲染结果,还有后面会讲到的球面visibility信息。Mesh表面的最小二乘法拟合效果依然不能达到最优,玩家应该不太会接受。
右图是我们和数据团队通过一些古典人工智能,比如遗传算法的手段去用LDR特效拟合HDR效果的例子。但这些方法搜索空间太大,收敛缓慢,而且效果上也不如人意,大多数情况不如专家手工效调整果好、通常用于初步调整。
那既然这些算法都有着诸多的问题,那是否有一个通用的更好的解决方案呢?在这个问题上,我们钻研了很久,可能花费了上年的时间,最后找到了一个方法。
我们先抽象一下问题看看本质。假设我们有一组参数集(包括模型,材质,shader等等),分别通过最优品质渲染和拟合渲染,生成了一组不同视角的对应图片。现在图片之间出现了差异,我们如何通过这些差异反向调整参数集,使得它们后续的差异尽可能小,这就是自动拟合系统的一个本质问题。
首先这是一个非凸优化问题,但可以通过AI中常用的梯度下降算法来解,但梯度下降需要梯度传播,渲染不是简单的多项式,是一个非常复杂的非凸优化问题,只能使用梯度下降法,但渲染是GPU上的硬件过程,原本没有梯度概念与生成方法。那是不是无解了呢?
好在近年来学术界提出了一个可微渲染的理念,将渲染作为一个函数,通过对这个函数的巧妙设计,能对我们的参数集计算和传播梯度,这就是可微渲染要解决的本质问题。

下面我们来形式化的看一下到底什么是可微渲染。
可微渲染不仅包含普通的正向渲染过程,还包括逆向渲染过程,正向渲染大家都知道,就是从游戏资源生成图像的过程,而逆向渲染则是从渲染结果反推游戏资源的一个过程。当然这个理解是比较片面的理解,不过现在为了方便大家理解,可以这么来说。

我们来看一下上面这张图,普通渲染可以看做一个非常复杂的函数f,它的输入x包括相机位置、朝向,物体顶点位置,贴图,材质参数等等,f的输出就是渲染结果y。
这张图里,上半部分是拟合渲染,下半部分是Ground Truth渲染,输入分别是x_opt和x_gt,opt和gt分别代表optimize和ground truth,它们通过渲染函数f后能分别得到y_opt和y_gt当我们定义了屏幕空间的可微loss函数后,能求得两者的差异z,并对y_opt求得偏导。
如果渲染函数f可微的话,就能求得y_opt对x_opt的导数,最后通过链式法则就能求得z对x_opt的偏导。
当求得了这些参数集的导数之后,整个问题就变成了一个优化问题,就可以利用梯度下降一类优化算法,针对目标函数进行优化,以求得最优的参数集。另外在系统的上下游端还可以加入各种各样的神经网络,来做各种各样的应用。
有了可微渲染之后,上面诸多问题的统一解决方法其实就是,首先渲染高质量画面A,然后渲染Lod画面B,在屏幕空间求得两者的画面差异Loss,然后对待拟合参数求梯度,用梯度下降算法求解参数的一个最优解。Loss函数其实有各种各样的。待拟合参数包括模型、材质参数、贴图,甚至shader函数等。

所以剩下的核心问题就是如何使得渲染可微分。当然广义来说渲染包括光栅化渲染、光线追踪渲染、神经渲染等等,今天的时间关系,只能讨论光栅化渲染这一部分。
和正向的渲染过程不同,逆向渲染需要对大量的参数求导,这是个很难的问题。比如一张1024*1024的贴图就有着10的6次方左右的参数量。对于如此大量的参数求导,普通的Finite Difference算法肯定不行。
而PyTorch和Tensorflow中的自动微分技术也无能为力,因为他们是为线性代数和神经网络计算所设计的,普通的神经网络应用中只会生成几百个计算密集型操作,比如矩阵向量乘法或者卷积等等,而渲染计算会生成巨大的计算负载不均衡的计算图,性能和内存都吃不消。

下面我们会详细来介绍怎么去破解这些问题,实现一个高效的光栅化可微渲染器。
02 可微渲染管线实现
下面会按照这个顺序来介绍,首先是可微渲染管线的顶层架构,然后是可微GPU仿真的实现,即如何让光栅化器可微分。接着是可微Shader编译器的实现,因为除了光栅化器需要可微之外,Shader也是游戏中重要的一环,它也需要可微分。最后简单介绍下引擎资产服务器,它负责将引擎游戏资产提供给我们的可微光栅化器进行拟合和学习,并将结果转换为游戏资产。
首先我们来看下可微渲染管线的整体结构图,主要包括分布式训练单元和可微GPU仿真。
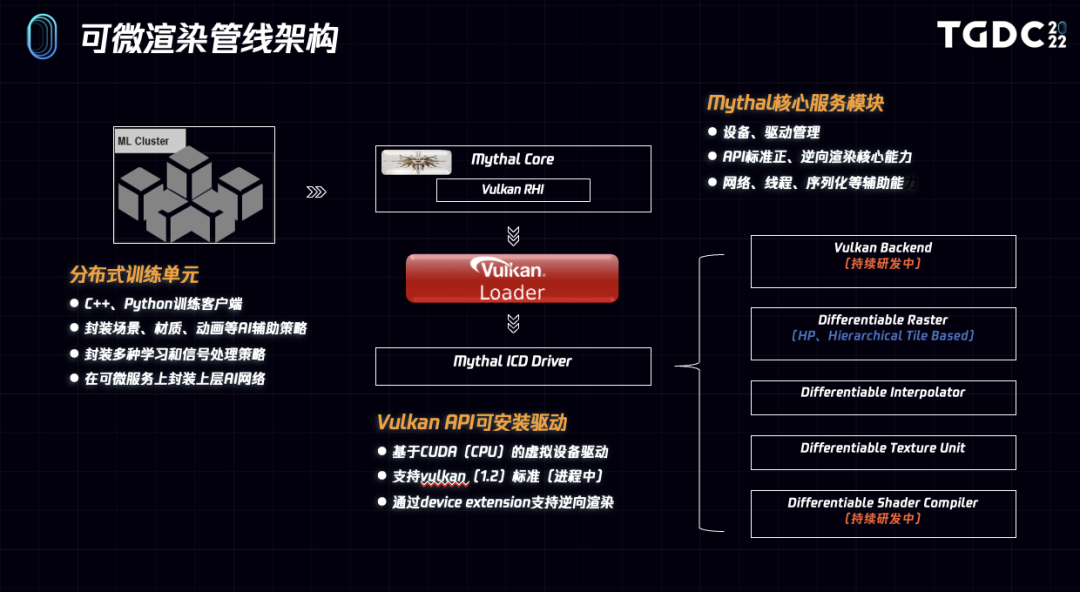
训练单元客户端封装和提供场景、材质、动画等数据,并配置各项学习策略。
Mythal Core提供核心的可微光栅化器,在当前版本中,我们已经在CUDA/C++上实现了完整的高性能正向、逆向渲染过程,GPU版本性能上完全满足业务常规的资产辅助生产需求。其中核心的rasterization、interpolation、texture sampling、shader等部分都是支持可微分的。
此外,我们也在追求方案的标准化,为此我们正在一个分支上将mythal的渲染核心封装为一个满足vulkan驱动标准的虚拟GPU,适配vulkan 1.2标准的API接口
下面我们重点介绍下Mythal Core的设计和实现。
对于Mythal的渲染核心,首先我们面对的就是“易于分布式部署,和高性能”这两个需求,我们参考了大量移动GPU的设计理念,并且也借鉴了很多现代GPU硬件和商业GPU仿真软件的优秀解决方案。最终以Hierarchical Tile Based Rasterization的方式构建整个光栅化过程。
在这种层次化的结构下,一来可以在Binning和Tile等不同的粒度上去组织和部署任务,非常适合未来灵活的部署需求。另一方面,Tile Based的结构更加Cache Friendly, 方便我们更好地使用设备上的L1缓存。
那么在实践上我们也是如此,这种层次架构加上CUDA对L1缓存的强大控制力,各个阶段都通过“生产者”-“消费者”模式,在计算前先将数据upload到L1 cache中,后续大量实际计算时所访问的数据都固定在芯片的高速缓存里面。同时,层次化可以让每层有更小粒度的任务划分,也意味着可以方便地去利用warp级别的高性能同步机制。
最后,我们支持了许多当代GPU硬件上的重要feature,以满足高性能目标的需求,这里最右边的这个列表例举了一些HTBR的重要特性。

这里简略介绍下Mythal的正向渲染部分的核心Stage,主要包括triangle setup、binning pass、coarse pass和fine pass几个部分。
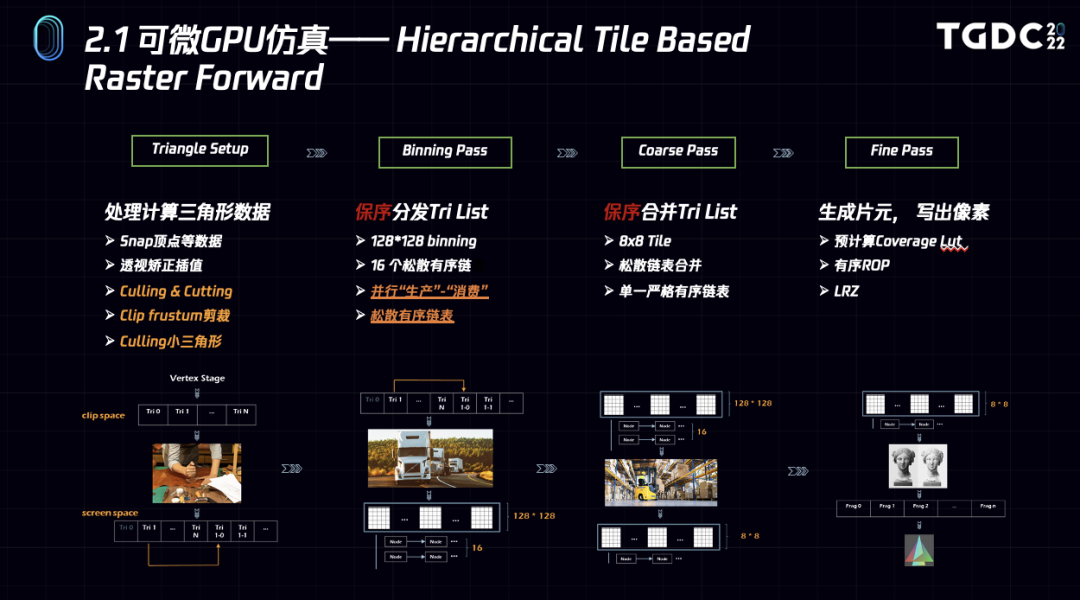
1.Triangle setup主要的任务是snap三角形的数据,并计算u,v,w等属性透视矫正后的插值平面方程系数。同时,这一步还包含了对三角形的裁剪和小三角形的clip,最终,我们有序地记录下处理后的triangle数据,如果这一步经由剪裁生成了sub triangle,我们会通过一个间接的index指向它。
2.在binning pass中,我们以128*128为单位将triangle有序地分发到这些binning中,为了提高并行化的吞吐效率,我们每个binning维护了16个有序的链表,每个链表节点包含一组512长度的数据,这样我们可以同时发起16个32 * 16的block同时进行triangle的分发。
3.在coarse pass中,每个32 * 16的block处理一个binning,将内部的16个链表合并到256个8*8的tile中,因为有序链表的特性,我们在合并的时候也可以通过index自省技术保持tile链表的严格有序性质。
4.Fine pass是最后一个阶段,我们处理tile中的triangle,为其生成fragment,经过early z后调用pixel shader,经过depth test后通过ROP写入到像素中。在这里我们每个warp(也就是32线程)处理一个tile,通过一个预计算的LUT简化fragment的生成算法,避免了逐片元地计算edge function。同时,还支持了LRZ, QUAD Pixel等现代硬件所支持的特性。
在mytal中为了支持多样化的shader,我们也会生成screen space的visibility buffer,这个屏幕空间的buffer包含了每个像素对应的material ID,以及clip space的UV。同时,我们在渲染器中借鉴了现代渲染API中比较流行的shader table和bindless resource概念,以满足deferred+流程中方便地对材质间接引用以及shader间接调用,这样mythal就可以在正/逆向渲染都能优雅地处理复杂材质。

有了Mythal的渲染核心,“《王者荣耀》”项目的所有标准的PBR材质,以及大部分特殊材质均能在mythal中100%的还原,和硬件渲染效果完全一致。mythal在2080显卡上以1024分辨率光栅化130万顶点,60万triangle可以控制在1ms以内,足够达到我们可微渲染服务的性能目标。

介绍完了正向渲染部分,现在我们介绍一下可微渲染的backward部分,即逆向渲染部分。
逆向渲染本质上就是渲染梯度的计算和传播过程,mythal在逆向上也是Auto Differentiation和Manual Differentiation混合的方式。
对于Auto Differentiation而言,我们在正向过程中构建compute graph,视输入和输出的维度情况采用正向或逆向遍历,算法统一简洁,非常适合处理比如shader这种多样和复杂的应用,但是对于渲染而言通常参数空间维度很高,存储压力大,带宽和cache missing造成的性能压力是制约这种方法的主要原因。
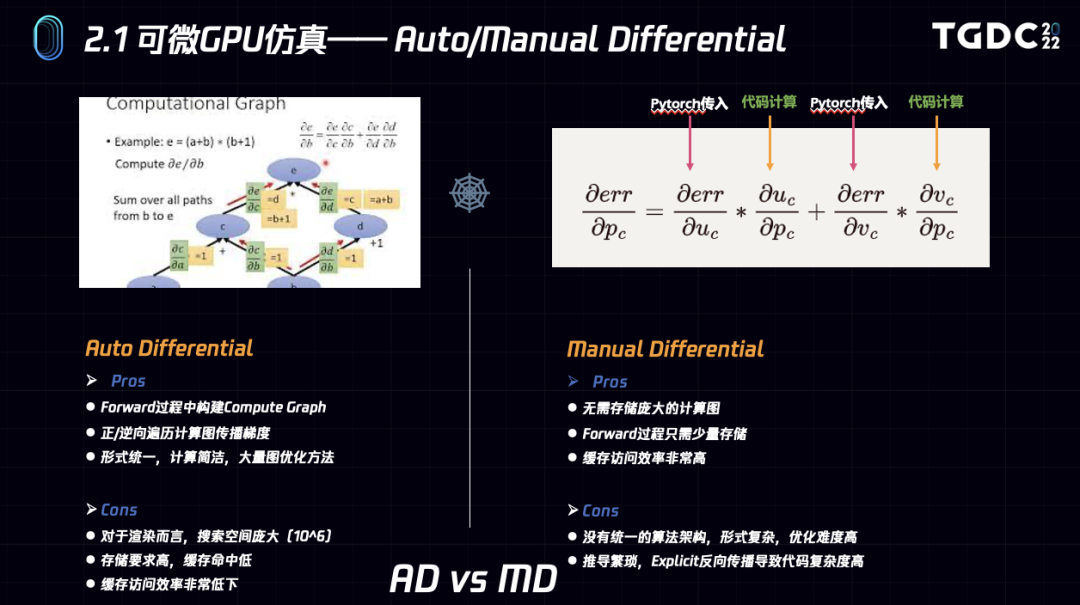
对于Manual Differentiation而言,特点和应用对象刚好相反,MD是通过求导链式法则手动计算梯度公式,不用存储计算图,缓存效率非常高,但同时算法特化严重,需要配合mathematica等工具来进行推导和验证,非常不直观,在mythal中我们用MD来处理相对固定的光栅化或其它硬件管线,并由Cuda高效实现。而渲染管线外的上下游部分,比如loss计算、数据处理、后处理等等都是用的PyTorch的自动微分功能。
采用这种Hybrid的微分计算方式既可以保证足够的应用通用性,又可以保证很高的性能。为了便于理解整个逆向的过程,这里还是先展示下正向的渲染流程。
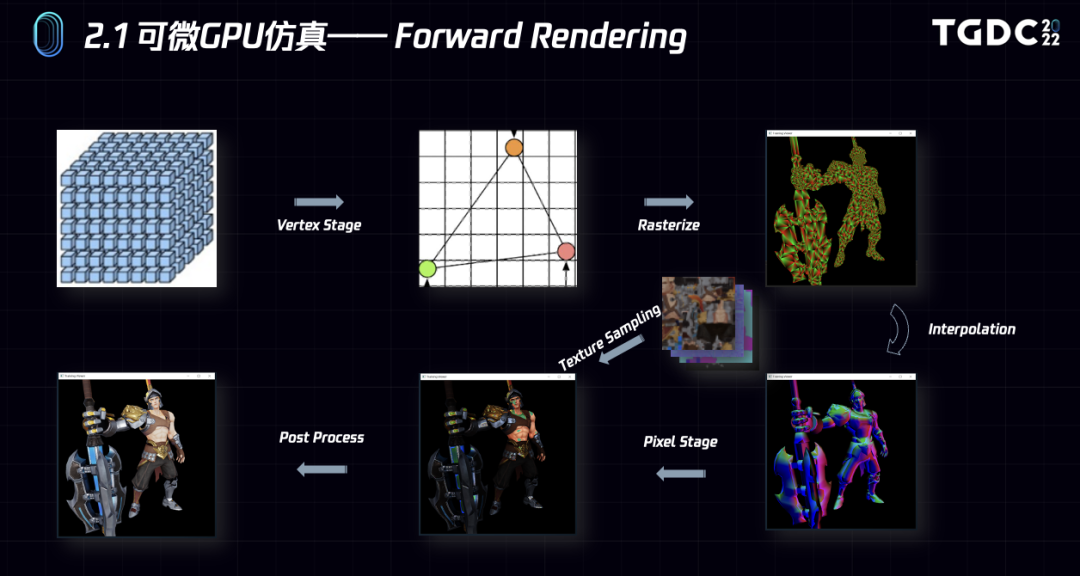
这个流程大家都比较熟悉,这里就不再赘述。下面是一个比较完整的逆向过程,这个图简化得非常多,流程比较复杂。
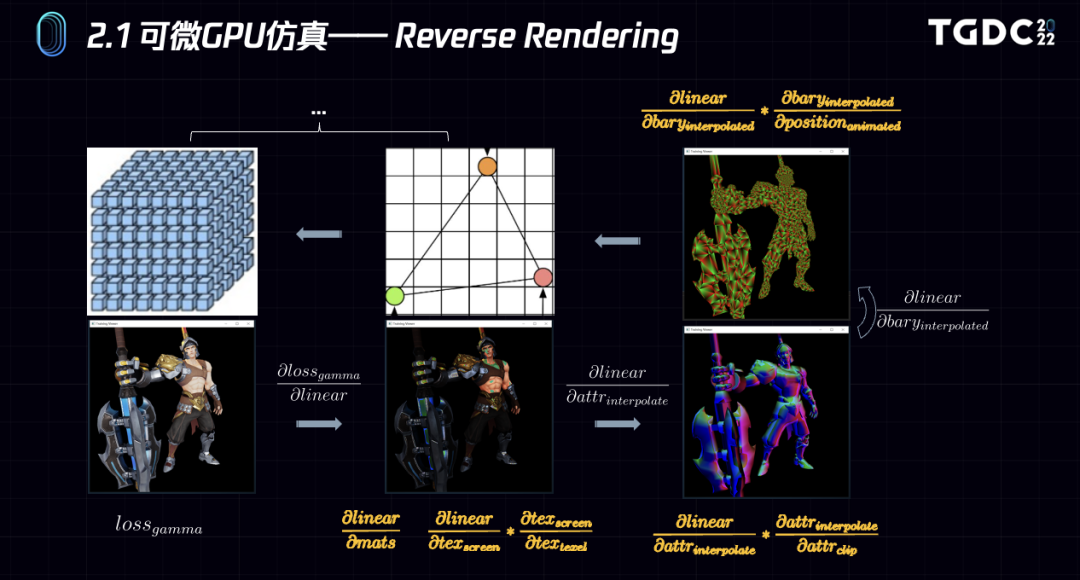
总体来说,我们从最终的gamma space image计算loss,然后借助forward渲染过程中存储的辅助信息,如clip space的barycentric coordinate, shader table, resource map等,将loss逐步地传导到参数集中, 配合Adam等optimizer, 完成整个appearance driven的优化过程。
详细的过程如下:
-
从gamma image的loss开始,传播到linear image,得到第一个gradient。
-
这个时候,借助visibility buffer ,bindless resource 和 shader table,我们可以得到当前像素的shader compute graph,材质参数集,插值后的texture coordinate。
-
接下来我们可以通过shader的compute graph求得linear image对material参数集的gradient,同时通过cuda实现的MD,求得linear image对各个texture上Texel的gradient。
-
梯度继续回传,先计算linear image对插值后 vertex attribute 的gradient,基于vertex attribute的插值表达式,可以得到linear image对clip space上vertex attribute的gradient。
-
同样的,下一步先计算linear image对插值后的重心坐标gradient,基于clip space position与重心坐标系插值的表达式,可以得到linear image对clip space vertex position的gradient,要注意的是,这个position是经过vertex stage之后的,可能包含了GPU上的蒙皮计算。
-
剩下的流程基本都相似,不赘述了。总结下就是我们通过AD和MD的能力,在复杂渲染函数f上相互协作进行梯度计算和传播,最终可以通过gamma image的loss,计算出我们需要的针任意坐标系空间中对应属性的gradient,从而实现mythal的逆向渲染过程。
整个流程还是很复杂的,这里省略了很多的推导步骤,可能大家只能得到一个感性的认识。
至此粗略介绍完了Mythal的核心渲染部分,那是不是就够了呢?当然不是,还有重要的一环就是如何实现可微Shader,毕竟最终面向玩家的渲染效果是由各式各样的Shader来实现的。
之前介绍逆向过程时提到过,我们在shader的处理上,采用Auto Differentiation的策略,用统一的算法来处理。但是,王者经过多年的研发和迭代,Shader极为复杂多样,我们需要对齐如此多的Shader效果,并且做到可微分,是一个艰巨的任务。
Pytorch支持Auto Differentiation,一开始我们是人工将Unity Shader翻译为Python代码,并人工保证渲染效果的正确性的,这样就能让Shader可微分了,但是这个过程非常耗费人力和时间并且难以迭代和维护。那这个过程是否能自动化呢?答案是可以的。

在探索过程中,第一版,我们首先使用antlr实现了HLSL和ShaderLab的语法子集,并实现了Unity Shader Lab到Python的代码翻译器。直接将Unity Shader翻译为可微分的Pytorch Python代码。

并通过AST子树替换解决类似宏替换之类的问题,可以将绝大部分的unity shader自动翻译成PyTorch Python函数。右图是一个shader部分片段翻译为python代码的例子。
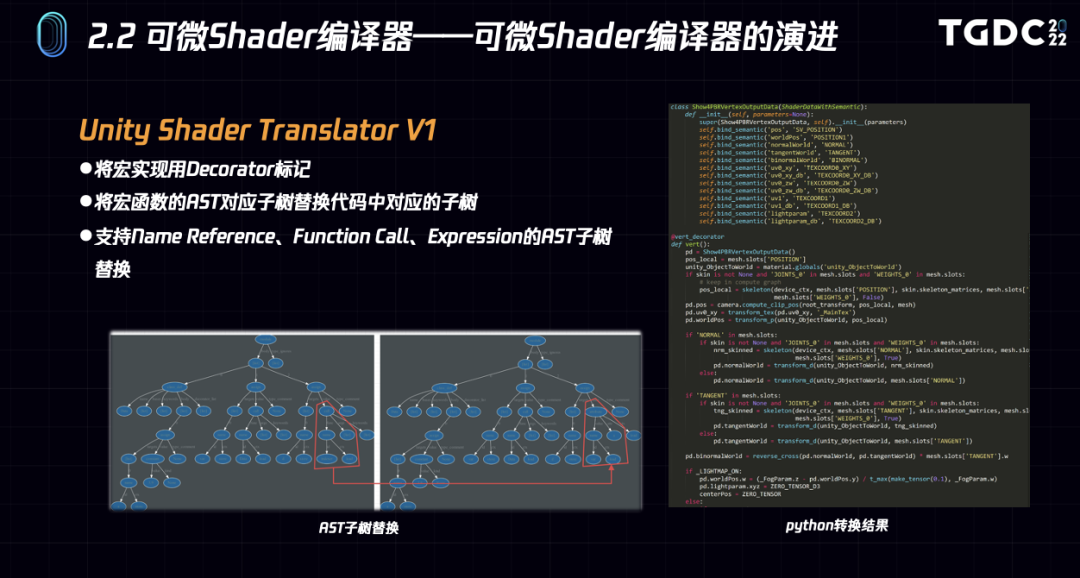
虽然基于grammer的语法翻译已经能解决“《王者荣耀》”Shader翻译的需要,但是业界现在有更好的方案,比如微软的DXC开源项目。经过调研分析后,我们选择跟进这个更加优雅的方案。
所以在第二版中,我们用clang ast visitor复用上一版本的ast转换规则对当前实现做了迭代,通过分析AST建立计算图,再通过计算图实现正向和逆向AD,最后再通过AST Rewriter生成目标函数的微分版本。这个方案结果更稳定,实现更健壮,而且llvm生态的一系列工具都能加以利用。
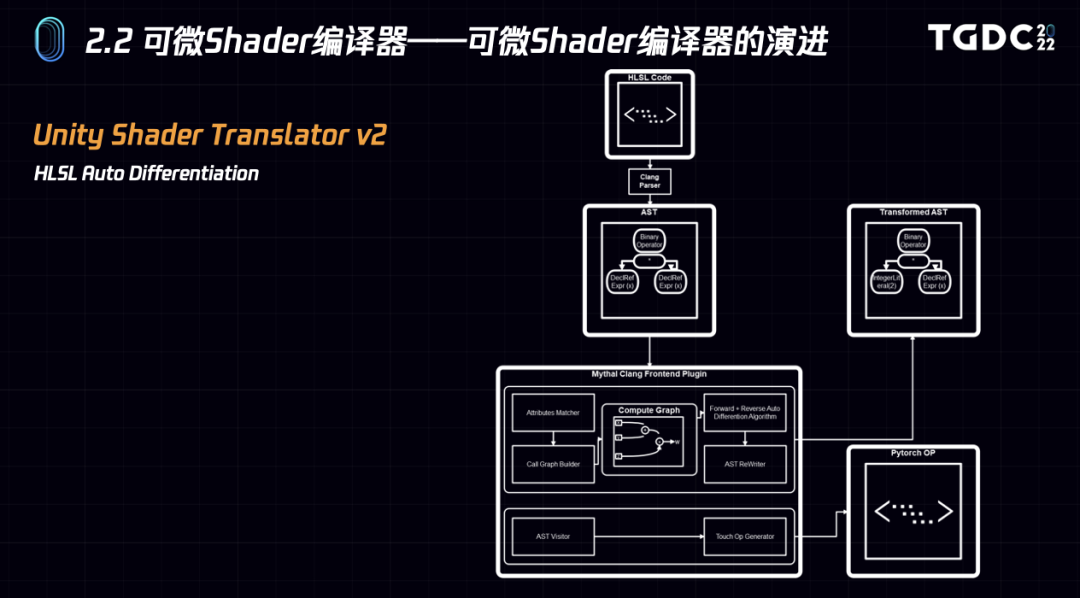
在clang插件实际项目应用中能直接复用之前的ast transform规则生成对应pytorch算子, 也能通过基于ast构建的compute graph来实现hlsl函数可微. 同时借助微软dxc的spirv后端我们也支持spirv的可微。

就如之前所说,mythal并非一个单纯的学术项目,我们的目标是工业化的智能资产辅助系统。在架构上,我们设计了一个C-S的辅助生产框架,mythal server负责对接引擎,对资产进行预处理便于学习和拟合,通过统一数据容器比如GLTF导出和写回拟合资产。
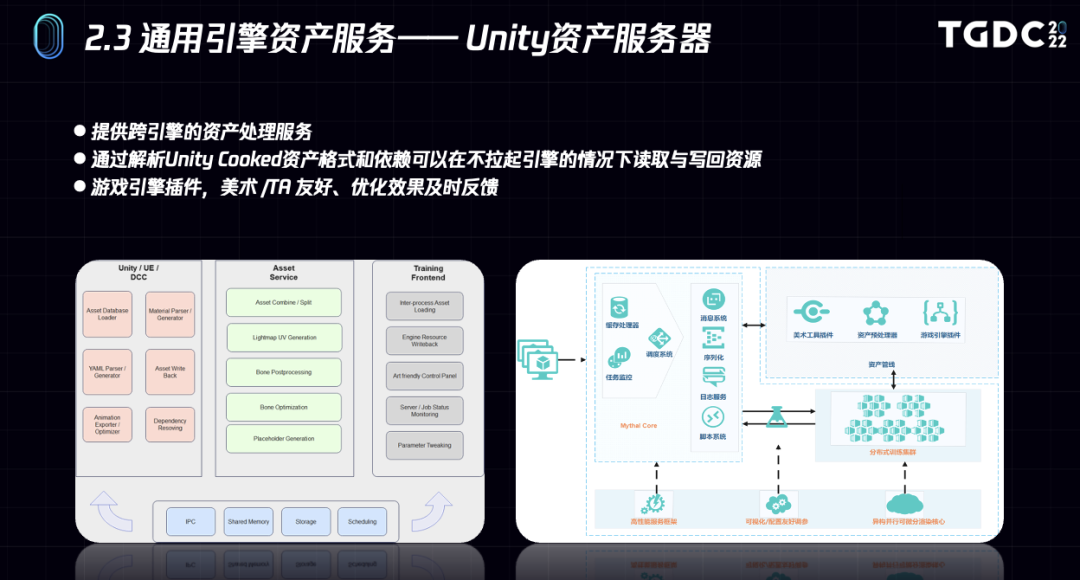
03 《王者荣耀》项目实践
上面介绍完了可微渲染管线的实现,接下来,我们将以5个实际应用的例子来说明mythal在“《王者荣耀》”项目中的实际应用。
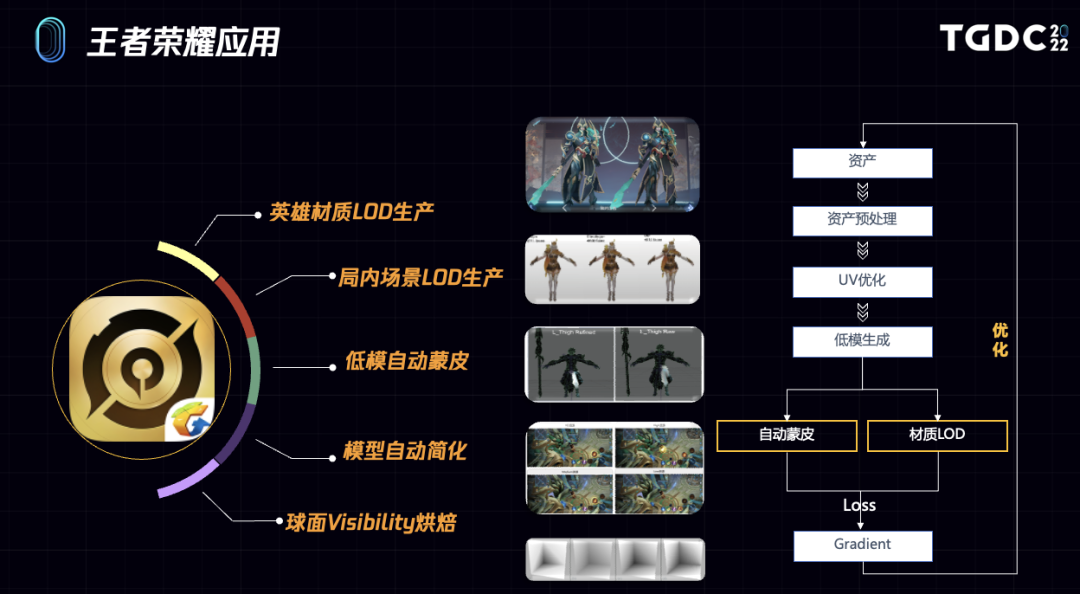
在Mythal中,我们搭建了一套完整的学习框架,支持不同的拟合与学习策略,完成不同的资产辅助生产任务。在实践中,我们第一个项目级别应用,就是为《王者荣耀》展示场景英雄和皮肤生产用于拟合标准PBR的Unlit LOD材质。
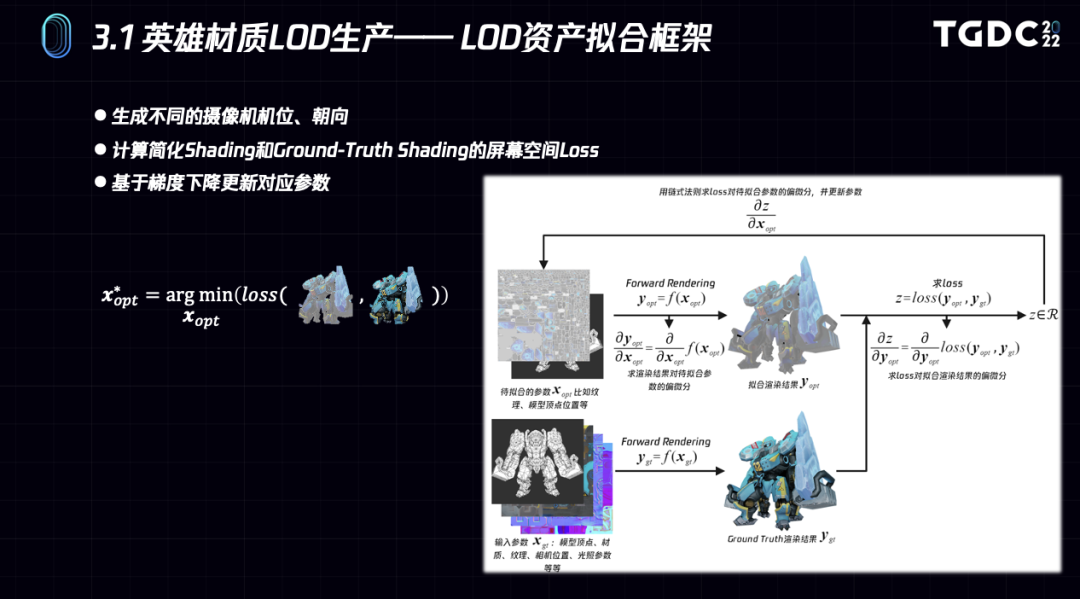
右图是通用的学习流程图。
-
第一步生成不同的摄像机机位、角色朝向。
-
第二步通过渲染器渲染得到原始角色PBR的渲染结果以及待拟合的角色Lod Unlit渲染结果。
-
第三步计算两个渲染结果的屏幕空间loss。
-
第四步计算梯度,并用梯度更新待拟合的参数,包括纹理和其他参数。
这是其中一个角色的拟合过程,左边是原始PBR效果,中间是Unlit的效果,右边是屏幕空间两者的差值热力图显示。
可以看到虽然只有单张贴图的预算,仍然可以拟合出来不错的渲染效果。
下面是另一个更为极端的例子,将PBR效果拟合到顶点色上面。
当然这个例子并不完美,最终效果和顶点的局部个数以及拓扑结构有关。但是对于局内的角色Lod来说,有些角色是可以用顶点色来代替的。
下面是角色展示Lod的真实例子,左边这个展示皮肤中的所有场景和角色都是Unlit渲染的。右边是其他的一些皮肤例子。

即便是最常规的PBR-Unlit的材质拟合应用,因为可微渲染极大的弹性和兼容性,也非常方便我们去尝试不同的数据拟合和存储方法,一个重要的理论就是基于画面信号的频率和重要度,拆分信号到不同的参数集中,由可微渲染自动拆分渲染结果,进行学习和拟合。
我们既可以用UV0也可以用UV1,也就是Lightmap Atlas来存储渲染结果,也可以用UV0存储明度,UV1存储颜色。

另外,为了达到最优的效果、性能和最少的包体占用,我们还做了不少优化,比如基于信号的UV分布优化、可微Quantization优化、HDR数据到LDR数据自动拟合压缩等等。由于时间关系,这里就不展开说明了。
下面是一些真机测试案例,无论是计算、带宽还是包体都有大幅的减小。在最低端机型上也能流畅运行。这个视频里,左边一列是原始PBR效果,右边是单张贴图的烘焙效果。
在2022年4月,Mythal项目的1.0版本部署到了美术基地,美术同学经过简单的培训后,能够以8套皮肤每人日的产能生产高质量的角色展示Lod资源,而对于传统手绘而言,7人日生产一套皮肤已经是比较激进的预估。
画质上,对标顶配效果的高品质LOD资产,在手机屏幕上,对非专业人员几乎无法分辨。
Mythal这套系统对高质量LOD资产的辅助生产上能保障产能提升70倍。效果上,除了梯度下降去保障一个local minimal效果外,Mythal还可以不断根据美术专家的经验优化算法,同时输出后续流程所需的辅助资产,支持效果的进一步迭代,非常适合为性能要求严苛的环境生产高质量资产。
同样的《王者荣耀》局内战斗对渲染的要求更为苛刻,为了同时追求极致的效果以及极致的性能,目前《王者荣耀》局内场景只有最高HDD配置是用的PBR动态渲染,其他几档配置都是用的PBR拟合出来的结果。
第二三档HD和High配置用的UV0+UV1 Unlit的渲染拟合,只是贴图分辨率有所不同。第四五档Medium和Low配置用的UV0+顶点色的Unlit渲染拟合,也是分辨率有所不同。

下面例子中对局内水面反射的物体进行了拟合。将12个反射物体拟合成了一个模型,并拟合PBR渲染效果到顶点色。另外需要注意因为反射物体有半透明效果,所以拟合的时候同时需要拟合Mesh的顶点位置,改变Mesh的形状。如何拟合较高质量的Mesh形状会在后面进行说明。
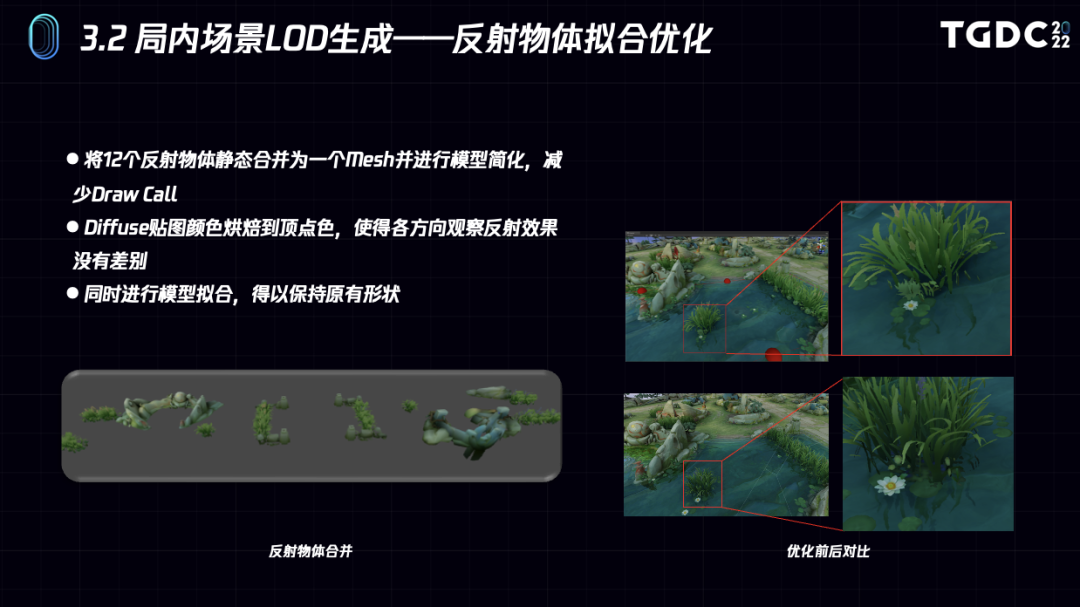
可以看到拟合前后的反射效果几乎没有什么变化,但是Draw Call、内存、带宽都能降低不少。所以用顶点色物体来做反射代理是完全可以的。
有了材质LOD资源后,我们还希望进一步生成Skinned Mesh LOD资源。下面我会分别介绍基于可微渲染做的自动蒙皮和模型简化方面的工作。
目前已有的自动蒙皮相关工作,例如(Geometry Base, Neural Network Based)等方法大多只考虑了基于静态模型进行预测, 但是没有针对特定动画表现进行优化。我们研发的LOD自动蒙皮系统则避免了这个缺陷,利用可微渲染结合神经网络,可以自动为LOD资产生成最有利于动画表现的蒙皮权重。
我们的自动蒙皮系统主要包含“蒙皮预测神经网络”和“基于渲染表现的蒙皮优化”两个主要模块。
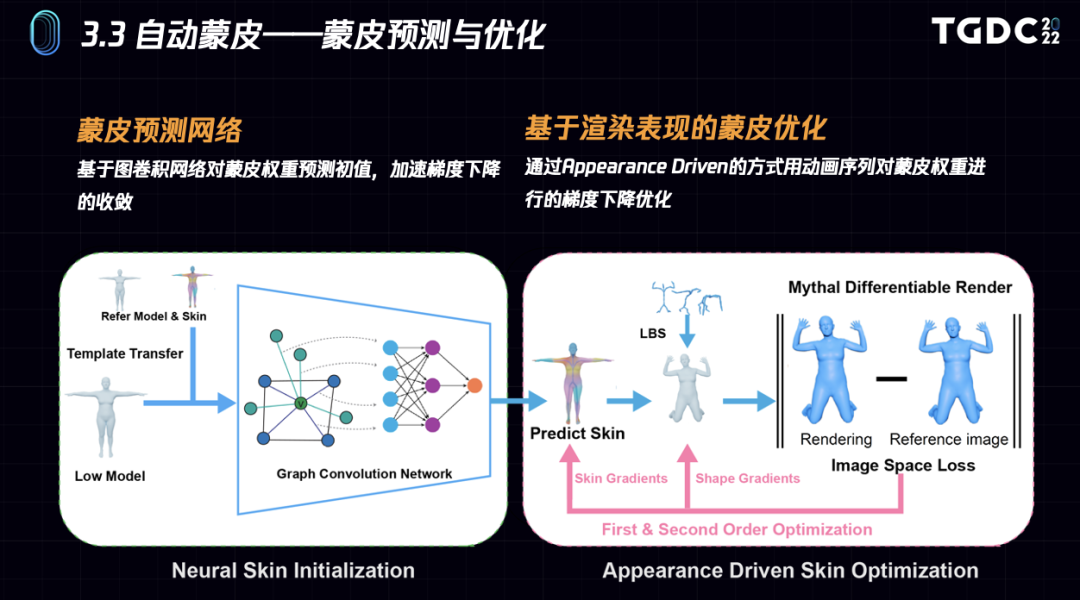
蒙皮预测神经网络会基于图卷积网络预测蒙皮权重初值,加速后续梯度收敛。基于渲染表现的蒙皮优化则通过Appearance Driven的方式用动画序列对蒙皮权重进行梯度下降优化。
我们的蒙皮网络采用了更适合处理Mesh数据的GCU图卷积层作为基本单元。为了提高网络的预测性能,扩大网络的感知范围,我们对网络结构进行了一定改进。
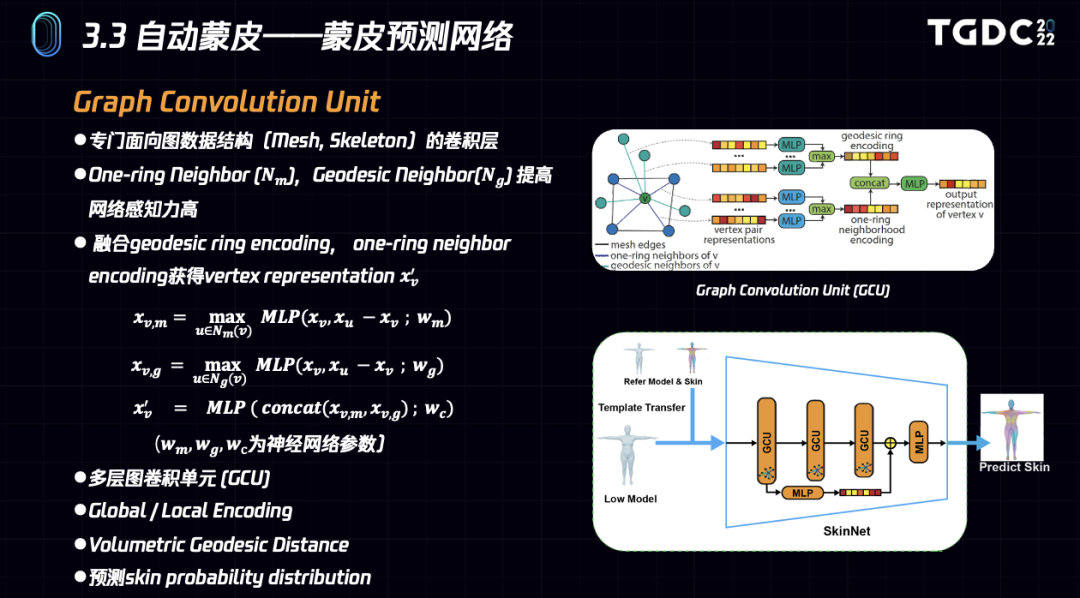
一方面,我们在GCU中除了应用one-ring neighbor还加入了geodesic neighbor,并通过融合两者的编码得到vertex representation。
另一方面,由于首层GCU输出包含较为全局的信息,我们会对其提取Global shape encoding与后续的Local encoding相融合.
网络中每个顶点的输入包含该顶点最近的K个骨骼的距离,以及对应的volumetric geodesic distance,最终预测蒙皮权重概率分布。
数据的多样性无疑是影响模型性能与泛化性的最关键因素之一。我们预先采用具有3000+数据量的开源模型数据库进行Pretrain,再用800+的王者绑定数据进行Finetune。训练Loss采用了交叉熵,Adam优化结合了Edge Dropout。
当身体的mesh与服饰配件较为靠近时,原始的网络可能会把这些部分的权重混淆,为此我们对模型进行了优化,我们在顶点输入中加入了骨骼到顶点的可见性矩阵, 以及身体骨骼类别的tag作为先验。优化后预测的精度有了很大的提高。
加入蒙皮预测后能够极大地加速蒙皮的收敛速度,仅需100轮左右即可收敛至原本需要500轮以上才能达到的精度。有效避免陷入局部最优。
蒙皮网络的输出结果对于动画表现还不是最优的,因此我们进一步基于渲染表现进行蒙皮梯度优化。

首先介绍一下蒙皮梯度的传递路径。在渲染forward阶段,最终渲染到屏幕的顶点位置v^c由vertex position v^b和skin weight ω_i基于Linear Blend Skin公式进行线性加权得到(K_i为骨骼动画矩阵),所以在可微渲染回传backward 阶段会首先得到形状梯度, 再基于线性求导便可以得到蒙皮的梯度。
然后介绍一下我们的优化目标。我们为了保证相邻顶点的一个形状和蒙皮的平滑性,优化目标中加入了 Laplace 正则项来提高相邻顶点的权重连续性。
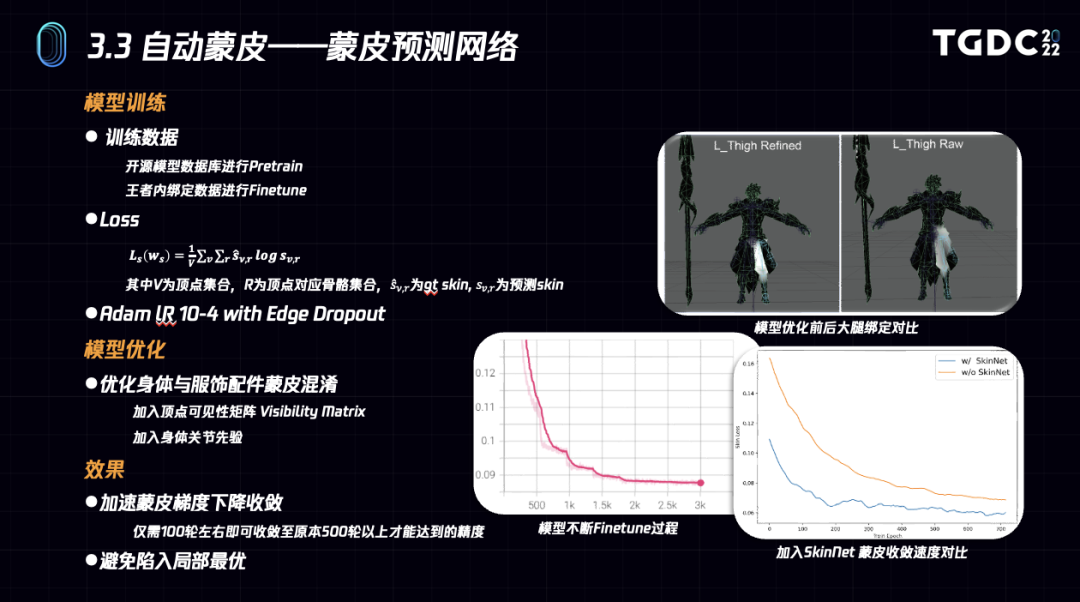
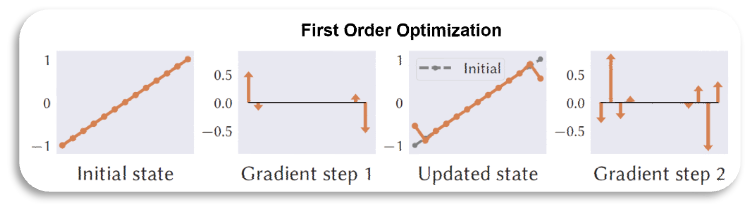
对于该优化目标的求解,可以基于常规的一阶梯度下降,不过这样会存在收敛速度缓慢,容易陷入局部最优的情况。参考学术界的最新进展,我们进一步采用了二阶梯度优化的方式来进行优化。
但是由于可微渲染部分的二阶 Hessian 矩阵 (∂^2 ϕ)/(∂x^2 ) 求解过于复杂,我们将可微渲染部分的Hessian矩阵用单位矩阵近似,从而得到近似的二阶优化的迭代公式。
下图是一阶优化和二阶优化的一个梯度传导示意图,二阶梯度能够传递到周围较大邻域的顶点,能够极大提高收敛速度。

下面的视频是通过虞姬高模的动画表现学习低模的蒙皮权重的一个过程,我们采用了一个很差的蒙皮初值来更好的体现算法效果。
从中可以看出我们的方案相比仅基于静态模型进行蒙皮预测的方法更能学出有利于动画表现的权重。并且可以看出利用二阶梯度优化可以加速蒙皮的收敛速度。
我们的LOD蒙皮系统需要输入低模进行蒙皮预测, 接下来我们会介绍如何基于可微渲染自动生成高质量的低模。
目前大多模型减面算法只是在模型空间进行计算,没有考虑模型的面导入渲染引擎后对于视觉重要性的影响差异。常规减面算法没有考虑带蒙皮的模型优化,简化模型的动画表现会受损。并且大部分的Remesh算法处理不了原本的纹理接缝,通常remesh后需要重新进行parameterization重新生成uv。
我们的LOD自动减面系统基于可微渲染来指导模型点面的优化,最大化的减小低模与高模间的渲染差异,保留原始UV, 并且可以基于前面介绍的LOD蒙皮系统保留高质量蒙皮。
在介绍减面算法前,我们先介绍一下基于可微渲染的形状拟合,这也是我们后续减面优化算法的基础。
下面视频是我们利用形状梯度从一个球体开始进行形状拟合的实验结果,我们采用了同蒙皮优化相同的二阶梯度优化,可以看出二阶形状优化相比一阶的收敛速度有了极大的提高。
我们将形状梯度拟合整合入模型减面算法,设计的算法流程如下:
-
我们会基于渲染误差不断选取对视觉影响最小的区域进行压缩 (在每个uv边界内交替使用 edge collapse, edge swap, edge split保留原始uv)。
-
对于每次新得到的顶点会基于形状梯度来进一步优化顶点的位置,减小渲染误差。
-
另外会在减面过程中考虑蒙皮权重,保留关节弯曲部位的顶点。
简化后的模型可以无缝接入前面介绍的LOD自动蒙皮系统,从而保留高质量蒙皮动画表现。
这个视频展示了我们减面的中间过程,可以看出,减面后的渲染效果还原度依然挺高。
下面的这个视频展示了我们用简化后模型进行LOD自动蒙皮的结果以及同Simplygon进行对比的结果。
从这个视频可以看出,在大概相同的面数情况下,在比较关键的部分,比如脸部、手部我们的减面算法仍然可以比较忠实地还原原始的渲染效果,而Simplygon已经出现了比较明显的失真。另外因为我们考虑了蒙皮权重,所以对于关节处的重要动画还原度会更好。
这个例子中,我们参考并优化了“使命召唤”的方案,改进了PBR渲染,增加了Visibility项来解决漏光问题,Visibility就是球面可见性信息,在渲染方程中就是其中的V项。Visibility能提供Directional Ambient Occlusion项来解决漏光问题。

我们要解决的问题可以抽象为:离线计算、编码 Mesh上任何一点球面可见性信息,在线解码任何一点的球面可见性信息,同时保证编码占用的存储尽量少,解码耗费的计算量尽量小。
最直接的存储方式是将visibility存储到贴图里,但是为了最小化包体、内存、带宽占用,我们需要拟合Mesh上的球面Visibility数据存储到顶点上。
下面我们来看下Visibility预计算和拟合的流程图。
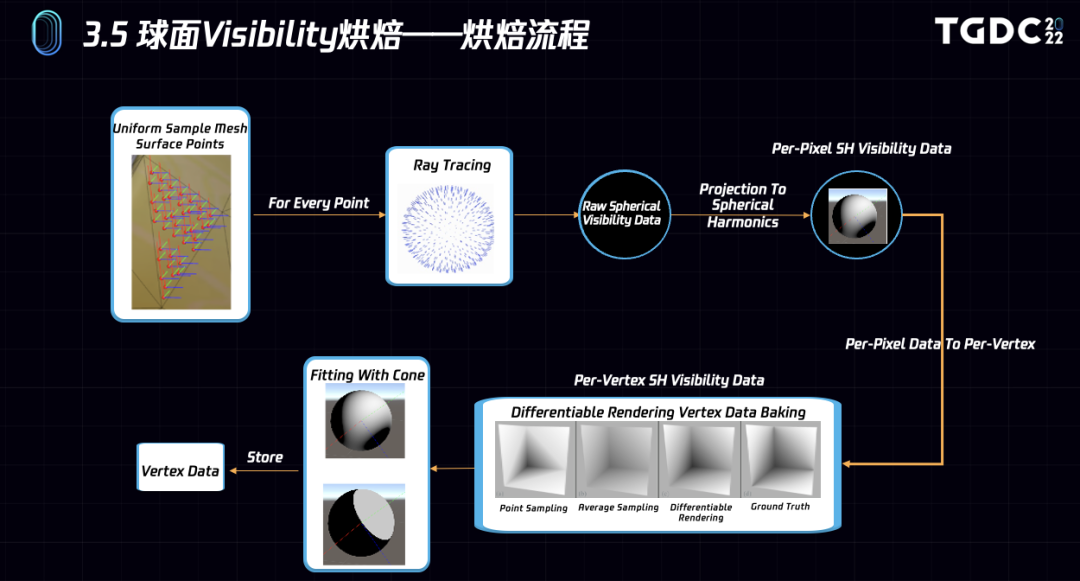
第一步在Mesh表面均匀分布采样点,然后对每个采样点做球面光线追踪,得到原始球面可见信息,投影到4阶SH值,目前阶段数据还是per-pixel的。
为了runtime开销尽量小,需要将per-pixel的SH数据拟合到顶点上。这一步和拟合顶点色类似,也是通过可微分渲染解决的,能最大限度地还原原始per-pixel数据的效果。
最后将每个顶点的4阶SH拟合成一个Cone数据,用Cone来逼近SH数据,每个顶点最终只需存储4个float即可。有了visibility,runtime除了可以计算AO,还可以计算directional ao,提供物理更为准确的渲染结果。

左图为AO的展示效果,右图为directional ao的展示效果。可以看出,对于金属很多的角色来说,directional ao能提供更为正确的渲染效果。对于金属很多的角色来说,directional ao能提供更为正确的渲染效果,而且我们省掉了以前的AO贴图。
这次分享已经到了尾声,第二章和第三章还有诸多的实现细节和难点在这次分享上无法一一呈现。除了上面介绍的各种已经落地《王者荣耀》的应用,可微分渲染作为一个基础框架,其实提供的可能性非常多,还可以做很多很多的事情。
比如可以基于Error量化分析自动生成Impostor,另外可微渲染除了可以辅助生产游戏LOD资源,还可以拍照生成材质、、拍照生成模型。辅助美术对最终渲染结果进行修改,然后自动求解到对应资源里面。这一部分其实我们正在做。
另外我们还可以实现基于光线追踪的可微分渲染器,去求解更为复杂的渲染问题等等等等。当然,这个我们也正在做。当然了除了这次分享提到的内容,可微分渲染还有很多的改进空间、发展潜力以及可应用领域,我相信未来可微分渲染技术可以帮助大家解决项目中的各种实际问题。
04 Q&A
Q:用于拟合学习的相机是如何摆放的?
夏飞:这个其实摆放它没有统一的方案,我们都是根据不同的应用去做的。一般来说相机可以Random摆放或者围绕感兴趣的模型进行球面地摆放。但是球面摆放和Random摆放,都会浪费很多的信息,浪费很多的摆放。因为它们看到的空间是相交叠的,而且它们离得比较远的情况下,看到的数据是比较小的。我们做了一个优化,先对Mesh进行稀疏Voxel化,再对Voxel进行SDF的计算。在Voxel里面摆放相机,而这些相机需要满足的条件是它的SDF距离,处在用户感兴趣的一个范围里面。这样这些相机之间的重合性会比较少,它们可以覆盖到几乎所有的区域。
另外王者在局外烘焙角色效果的时候,其实相机所在的位置比较少。对这种情况来说,我们进一步进行了优化。就是相机从美术提供的若干个Sparse Location进行Sample,它们还可以控制每一个Location的权重,这样我们可以对模型进行更好的覆盖和优化。
对于局内,大家都玩过《王者荣耀》,知道局内相机能处的方向其实是比较少的。我们也是在一个半球面的局部区域,让美术有工具可以去调,他需要感兴趣的一些方向,还有权重。这样针对每一个不同的应用,我们都可以做到比较优的一个结果。
Q:在LOD蒙皮优化和形状拟合中,你们都提到了二阶梯度优化,那么二阶梯度优化相比一阶优化各有什么优缺点吗?
夏飞:这个问题其实问得比较好。二阶梯度优化,它其实可以计算每一个顶点的Gradient,这个Gradient可以传播到更远的距离。那么在拟合学习的初始阶段,它其实可以比一阶梯度产生一个明显的提速,基本上有几十倍的提升速度。这样在前期的时候,我们可以快速地得到一个初始的比较好的解。这个解在最后阶段,再用一阶梯度优化来进行Finetune。为什么用了二阶梯度以后,还要用一阶梯度呢?这是因为二阶梯度优化它比一阶梯度优化,还有一个比较明显的缺点就是,它对细节的丢失性会比较多。因为像拉普拉斯或其他的应用里面,它传播得比较快,它实际上相当于把整个局部区域给抹平了。这样它对细节的还原能力比较低,所以在最后阶段需要用一个一阶梯度优化做一个Finetune,这样得到的效果是最优的。
Q:从目前的算法来看, mythal现在的算法属于比较基础的gradient based optimization, 后期有没有计划加入网络的支持呢?
夏飞:其实我们有用到神经网络的技术,比如刚刚提到的蒙皮优化和模型减面,我们就用到了神经网络。在比如说举个例子,在模型简化里面,我们第一波是采用了一个GCU的图卷积网络,来对蒙皮权重进行一个初始的预估。这样它可以极大地加速后面梯度的Converge的速度。而这个神经网络我们是在3000+的开源模型上,还有800+的《王者荣耀》的模型数据上进行Finetune的。当然了,可微渲染作为一个底层的技术和框架,它提供了精确的可微分计算,让整个渲染流程可微。当然渲染流程包括光栅化、Ray Tracing,它作为底层技术可以给上层的算法提供一个比较好的基础,上层算法可以用各种各样的神经网络进行计算。由于可微渲染和上层的神经网络加在一起,它是整个管线都可以可微,这其实是一个非常牛逼的能力。
在CV领域和三维重建领域,现在都已经用了大量的神经网络计算的一些能力。比如说Nerf之类的Neural Rendering,还有一些神经网络计算,它可以直接表征数据,还有计算函数。比如说它可以表示Mesh的数据,还有2D纹理、3D纹理的数据。最近的论文Instant Neural Graphics Primitives,甚至将神经网络和Hierarchical Hash Table结合在一起,做出了比较大的突破吧。
TGDC2022已于8月17日结束,想了解更多干货内容,可以点击下方链接进入TGDC2022官网回看。