
一、画风尝试:从 “美影厂” 模型 到 “敦煌”
会做这个方向的尝试是因为看到了一个很棒的国风水墨画 LoRA 模型:墨心。[1] 这个 LoRA 模型相信很多朋友都知道,可以谓之为目前表现中国山水画最强的 AI 模型了。

作者是我的朋友,由于其本人的期望,就不在这里署名了。他分享给我了一些经验,都是非常有价值的思考,所以也分享给大家。
1. 取法乎上得其中,让 AI 临摹的对象一定要选大师。墨心的数据集选的是明清两代的绝顶大师,包括:吴昌硕、郑板桥、任伯年等人。墨心能有一定的效果,其实是 AI 机器学习大师的笔意得来的。
2. 在数据集标注上一定要花功夫认真去描述,在自动生成的基础上,我是用 ChatGPT 帮我翻译成英文替换进去的。

上图是墨心作者提供的数据集案例,一共使用了 209 张图,对于每一张图都进行了领域内详细的标注,每张图训练了 100 次。数据集大多都是山水草木鸟,但 AI 学习了其中技法后将其 apply 到了肖像绘画中,这真是神奇之处。
按照墨心作者的方式,我用 70 多张上海美影厂早期作品的截图,以 Deliberate 模型作为底模,通过 LoRA 的微调方式做了一个上海美影厂的 LoRA,并且用其生成了一些迪士尼的公主和王子。效果还不错。

在这件事上,我还感受到墨心作者对于国画本身深厚的了解,我想这是让他能够训练出这个模型的主要原因。我想起前不久去北京看敦煌的壁画展。

此次最大的震撼不是在于壁画自然氧化后留存下来颜色的美感,而是敦煌壁画的叙事方式:他会把一个故事不同时间点的事件放在一张图里。
比如《九色鹿》是从画面两端双线叙事,到画面中点处双线汇合后迎来大结局。而《舍身饲虎图》则是因果和轮回都放在了同一张图里。

这让我想起了特德姜的小说《你一生的故事》,我猜测敦煌时期人们的世界观会不会也是:“我生活在人生的所有时刻。”
目前的算法模型的产出很符合我们现在看待世界的线性的方式,呈现的是“此刻” 或者“某个状态”。现在已经有很多很好的绘画产品能够仿制出敦煌的风格。

但是 AI 知道文殊菩萨骑狮子、普贤菩萨骑大象吗?如果我们真的有所谓 legacy 可以留给后代或者 AI,不应当只是色彩或构图,还有故事和我们看待世界的方式。
如果我将这种 “异时同图” 的叙事逻辑作为标注给到 AI,让他学会这种叙事方式,把故事不同时刻不同状态,在同一张画里显现,是否有可能教会 AI 一种新的叙事?
我们需要的可能不是更多的算法工程师?还是更多垂直领域的从业者懂一些算法。
二、角色尝试: “恋与制作人” 真人卡牌
探索角色模型的原因,主要是受了堪云工造老师 [2] 赛博 Coser 系列的启发。
据堪云老师本人描述,这是在基于 ChilloutMix 模型的基础上,用二次元角色的立绘提取角色特征训练 LoRA,进行生成后得到的。

基于他的思路,我在主要是画女生模型的 ChilloutMix 上,通过喂主要为二次元男性角色的立绘,对模型的角色特征进行纠正,做出了画男生的 LoRA 模型。

LoRA 的神奇之处还在于,你可以叠加不同的 LoRA 来一起使用,除了写实模型以外,我还做了以下尝试:(使用模型的下载地址都标在了文尾)
↓ 角色 LoRA + 贴纸模型 waves-chibi-style [3]
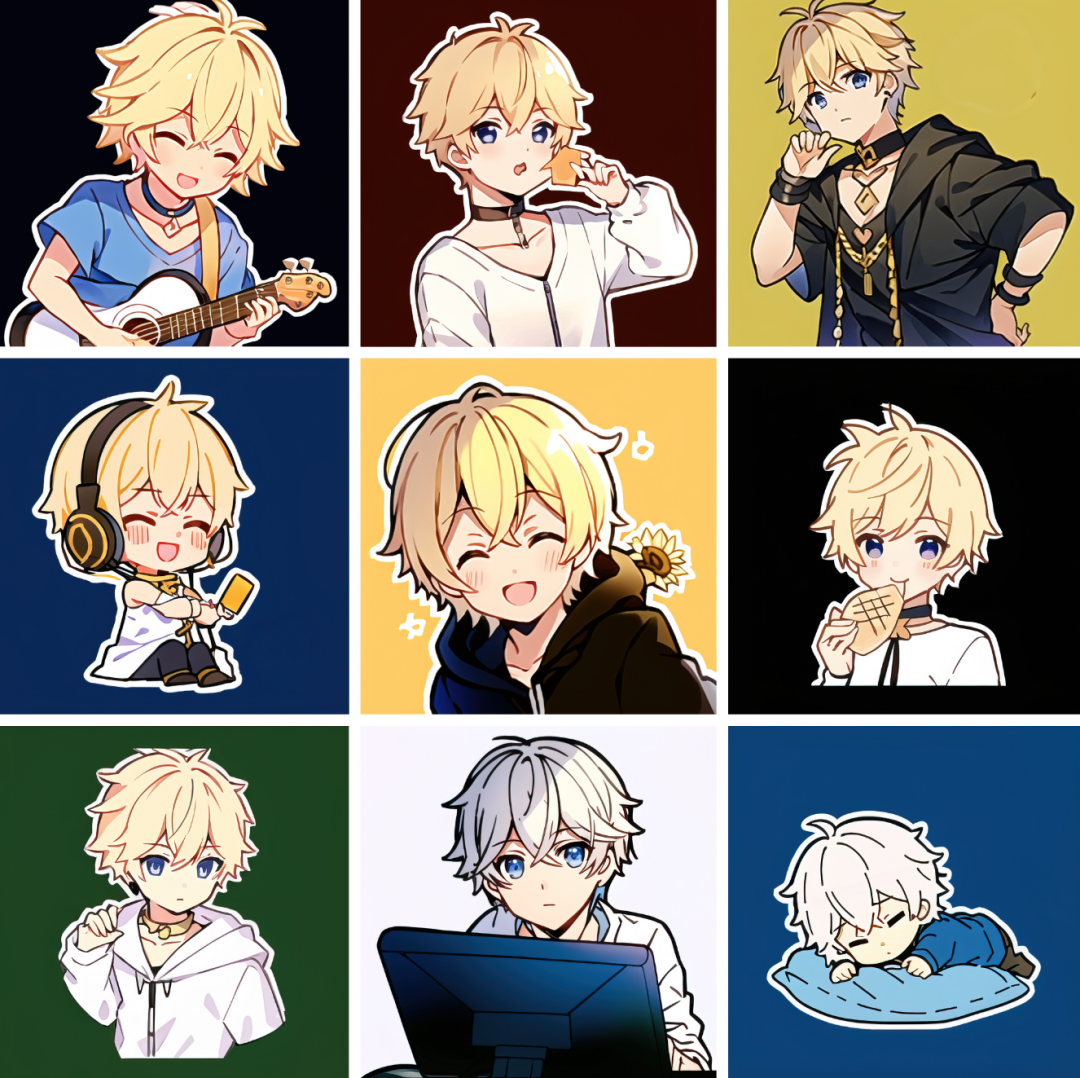
↓ 角色 LoRA + 大头娃娃模型 bigheaddoll_v1 [4]

↓ 角色 LoRA + 古风模型 moxin1.0 [1]

↓ 角色 LoRA + 吉卜力模型 StudioGhibliStyle [5]

角色特征、风格特征可以使用 LoRA 来成为可独立管理的资产,在需要时通过 AI 来进行融合创作。
同期,一项新的技术进入了我们的视线。ControlNet 赋予了创作者在与 AI 协同工作的过程中更大的控制力,AI 可以根据你提供的线稿、深度图、姿势图等,进行完全遵循你个人创作思路的生成。逗砂的公众号文章做了非常详细的介绍:《游戏要结束了:ControlNet 正在补完 AIGC 工业化的最后一块拼图》
在探索 ControlNet 期间,我也做了一个从线稿转成图的效果尝试,以及图像在不同参数下生成效果的变化。


这个测试结果也得到了 ControlNet 开发者本人的转发和认可。
这件事情我还蛮开心的,知道自己不仅受益于开源社区,成果还能反过来激励到开发者,或者我的分享对于开源社区是有益的,这对我来说是很重要的事情。
ControlNet 还可以多层控制:比如人物姿势和背景线条分开控制,人物姿势和深度图分开控制等。

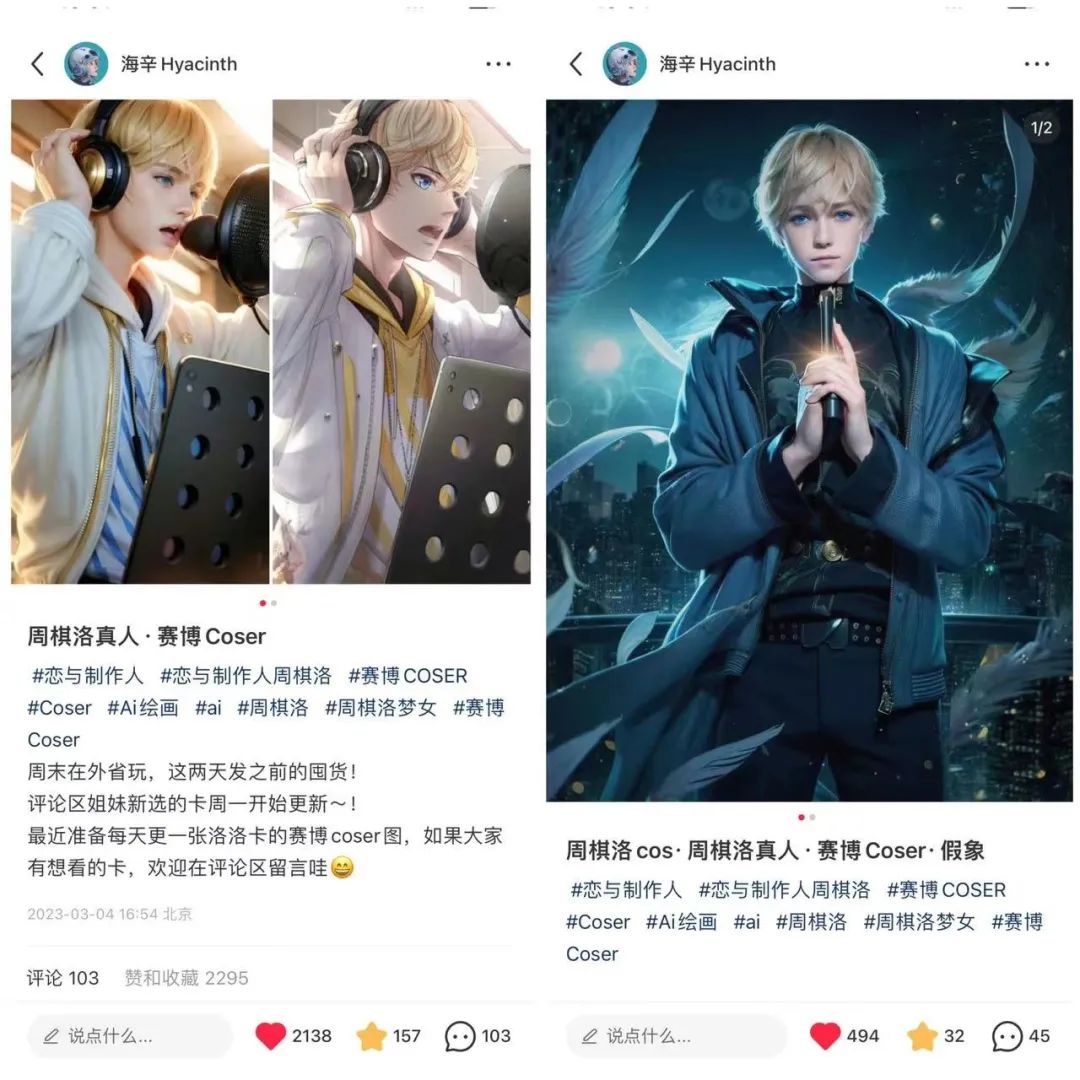
有了这项技术的加持后,我开始使用自己做的角色 LoRA 将《恋与制作人》的卡牌角色周棋洛,进行了真人复活。
以下图片左边是卡牌原图,右边是结合 LoRA+ControlNet Canny 模式,进行的赛博 coser 卡牌生成。




这个系列在小红书上也得到了很多用户的喜欢。我因此也有一个体会:如果要拿 AI 做内容的话,得是真的对这个内容有了解/感兴趣/喜欢的人来做。
三、应用尝试: “永劫无间” 二创美宣 到 “AI Bubbles” 虚拟时尚杂志
在更新了一段时间的赛博 Coser 以后,我对 LoRA 训练、ControlNet 使用都比较熟悉了。于是我开始想是否有机会用 AI 的流程,来出一些游戏美宣质量的图。
这个时候另一款我在玩的游戏,永劫无间,出了一个叫做胡为的新角色。我去测试服玩了一下后决定做这个角色的二创美宣图试试。

我先进入测试服游戏界面,截了一系列这个角色各个角度的图片,然后训练了这个角色特征为主的 LoRA. 其中底模的选择很重要,因为游戏风格的原因,我选择混合了古风和写实真人的模型作为底模。
LoRA 模型训练好后,即可在结合 ControlNet 的基础上生成指定姿势的写实风格的人像。最后再用 Midjourney 生成了虎纹和背景火焰的元素充实画面,在 Photoshop 里叠加了一些布料做旧和火花的特效。

虽然在装备的质量和细节上还有许多需要提升的地方,但目前大体的效果至少我个人是非常满意和喜欢的,这张图从模型训练到最终的合成渲染,一共花了 2 天时间。
最后再和大家分享一个应用尝试。写到这里我舒了一口气,终于要写完了 如何让 AI 学习指定风格的服装,然后让赛博模特来穿出效果图,是最近 AIGC 圈子里在关注的一个子方向。
我和我的朋友 Momo 桑做了一个以 y2k 风格为主的服装搭配 LoRA 模型,并以 AI 作为“模特”,以此 LoRA 模型作为“造型师”,尝试做了一个虚拟时尚杂志。

我们在训练 LoRA 的过程中喂了许多 y2k 风格的单品样图,在模型生成的时候,通过描述词尽可能精准地去贴单品的版式和特征。对于常见的款式来说是有效的,对于花纹比较繁复的还是容易翻车。(不过我们逐渐在单品控制上效果越来越好,如果对本项目感兴趣也可以关注我们的项目小红书@AI Bubbles泡泡)


Reference
[1] 墨心:civitai.com/models/12597/moxin
[2] 堪云工造:afdian.net/a/kanyon
[3] 贴纸:civitai.com/models/4379/toru8p-waven-chibi-style
[4] 大头娃娃:civitai.com/models/16643/big-head-doll
[5] 吉卜力:civitai.com/models/6526/studio-ghibli-style-lora