
今年的游戏圈依然面临着腾讯系游戏的碾压式进军,几乎做一款成一款的现状,让市场的一半都流向了这家公司。究其原因,是腾讯建立十多年来的大数据体系,以及由此衍生出的用户研究理论和产品调优模型。他们的大数据不是摆设,而是真正能帮助游戏挣到钱的方法论。
曾在腾讯任职四年的吕承通,一直和游戏打交道。在他看来,大数据体系的实际运用是很广泛的。
比如通过提取已经在游戏中产生付费行为的玩家的特征,对这些玩家进行建模,得出了一些特征值,然后将这些特征模型拿来匹配那些从来没有付费行为的玩家,找到了一部分与付费玩家特征值相似度非常高的免费玩家。
按道理来说,这些玩家与付费玩家的行为习惯非常相近,是存在付费可能性的,这部分玩家存在付费意愿,但是并没有找到合适的付费场景来产生付费行为。所以可以根据这个结论对这部分玩家订制精准的营销活动:“幸运玩家”活动。
首先,通过一套算法计算出这些玩家的付费意愿的强度值,从0、0.1、0.2,到0.8、0.9、1。系统计算出玩家的付费意愿后,会发放给玩家一个道具,再根据意愿强度提供打折优惠,强调“仅幸运玩家享受”这种优惠,并且付费意愿不高的玩家就给足够多的折扣,付费意愿高的玩家就给不是很高的折扣,让不同付费意愿强度的玩家都有可能进行购买。
“幸运玩家”活动给玩家的体验就是,并不是所有人都能享受这个折扣,他是这么多玩家里为数不多的幸运儿,甚至可以去贴吧里发个帖炫耀一下中奖的消息。于是从结果上看,游戏的口碑和付费率都得到了提升,而这套模式也因为非常成功,被运用到了腾讯的很多重点产品之中。
说到这里,我们应该能想起来不少平时在玩游戏时的经历。可能你因为某款游戏的优惠活动而成为了付费玩家,并且一不小心就落下每次打折就想充钱的“坏”习惯。而充钱的欲望也是随着优惠力度而浮动,也就是说你的消费习惯早已被游戏打上了标签,你的欲望大多数时候也都是被支配的。

当然,非腾讯系的厂商也能依葫芦画瓢,找出有付费意愿的免费玩家,推出针对性的转化活动,来拉高自身产品的各项数据。
但问题来了,腾讯是靠大数据定位玩家,但如果你是非腾讯系的厂商,要靠什么来定位?怎么去定位?
国内现有数据服务体系的缺点
相信游戏从业者对数据不可能不敏感,对大数据的意义也各有理解,只是碍于国内目前具备研究、实践大数据的公司并不多见,所以大部分人并没有经历过使用大数据带来突破性改变的情况,往往是依靠自身经验,来完成游戏数据分析的过程。
加上国内现有的数据服务体系,与大数据的分析体系还存在本质上的区别。
第一,SDK式数据统计的局限。国内的游戏数据采集,通常是以游戏内接入SDK,对玩家的不同行为点进行收集,然后通过数据统计的形式呈现出来的。在过去,这确实是非常实在和有价值的数据服务,因为玩家行为的结果能很直观地体现在数据趋势中,比如玩家在某个时间段的活跃度、每天的登陆次数、在什么时候付费、通过什么途径付费等等。然而SDK能够获得的数据是有限的,更多更全的数据,都以日志的形式记录在服务器本地。
第二,只能看到已经发生的事件。通过SDK采集到的数据,都是玩家行为产生过后才表现出来的数据,也就是当游戏的ARPU值下降了以后,大家才能看到下降,当游戏活跃度减少了以后,大家才能看到减少。所以运营的过程当中,难免遇到一些很被动的局面,比如营收下降后,为了保持产品的成绩,不得不做一些拉高营收的活动,刺激玩家付费。
所以国内现有的数据服务体系很多时候,只能在损失产生以后在作出补救措施,这与大数据相比能做到的事非常有限。
用外围大数据分析,预测玩家的游戏行为
在腾讯就职的期间,吕承通就在思考和实践如何将数据挖掘和机器学习的技术应用在游戏领域。在他看来,目前已经在做的系统还有很多可以完善和深入的地方。而目前市场上最大的空白,就是对玩家行为的深度挖掘,所以这就成了切入点:从玩家的行为数据中分析出,将来游戏可能发生什么事情,会出现什么样的走势。即使现在游戏表现良好,但有哪些问题可能在将来发生。
吕承通从腾讯出来后便选择创业,并建立了专注于数据服务的ThinkingGame。目前他们已经对接了30多个游戏论坛、20多家渠道,以及30多家行业媒体,从玩家口碑、行业趋势、排行数据等三个方面进行深度的数据挖掘。
但是数据挖掘并不是传统意义上的数学统计,在信息检索到结论导出的每个计算环节,他们都有自己的一套算法,这些算法由公司的专业团队进行研究,团队目前的成员就有数据挖掘方面的博士,专门从事挖掘算法的研究,另外,吕承通本人也是文本挖掘方向的博士。
“在算法理论方面,我们有非常强的竞争力,目前系统很多算法都是我们团队自主研发的,下半年我们会把原创算法写成学术论文,往相关领域的会议期刊投稿,以得到更多同行的认可。”吕承通对ThinkingGame的技术实力很有信心。
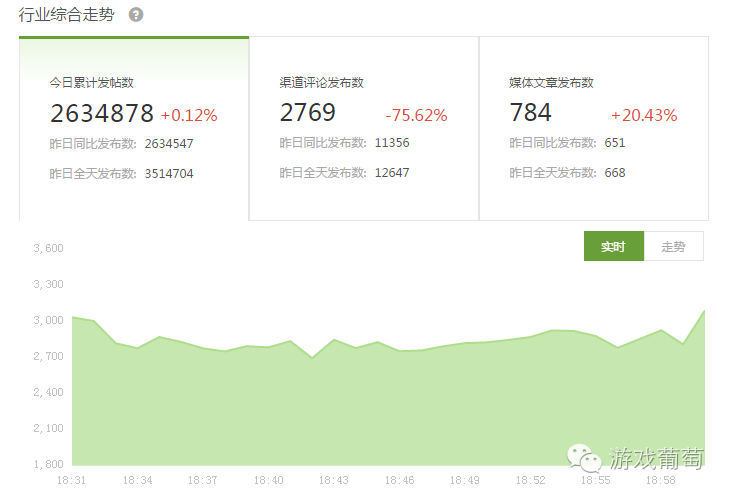
对大数据而言,基础样本量需要足够多才能称之为大,于是ThinkingGame的第一项基础任务是足够全足够多的收集数据信息。它通过收集各大平台、论坛、渠道中玩家对游戏反馈的数据,并进行每两秒更新一次的实时监控,在官网就能看到这些数据的即时更新,以及更进一步的数据统计。
而在吕承通看来,目前很多人为的数据收集工作是非常低效而且不全面的,即便能做到很全消耗成本也是很难控制的,在他的设想中,随着算法的完善,ThinkingGame这套监控系统的第一个便利之处,就是基本能代替游戏公司进行广而全的论坛、贴吧、渠道评论的监控工作。
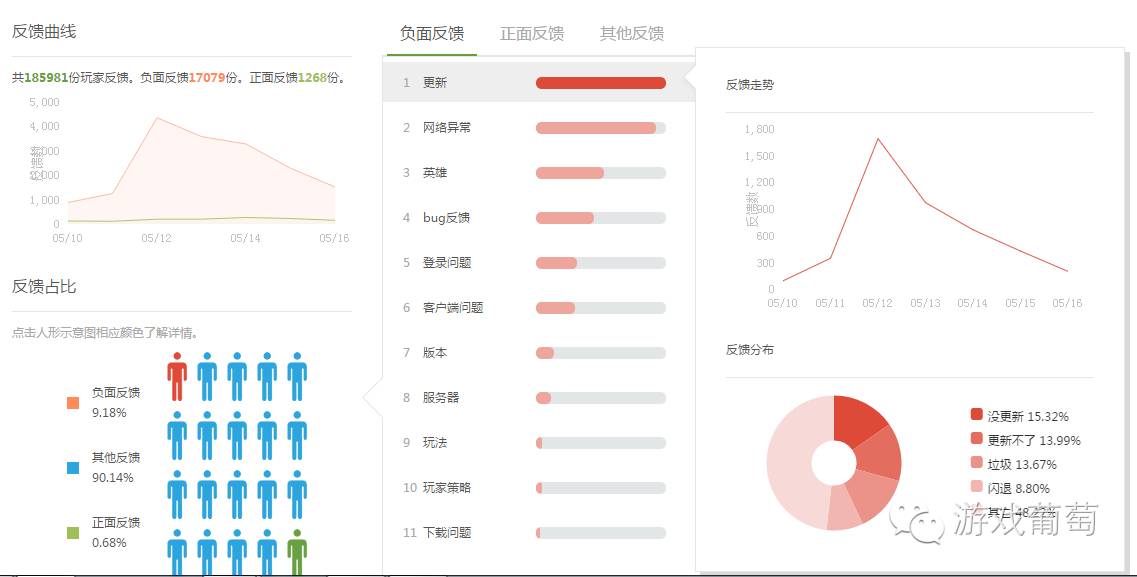
在采集大量的玩家反馈数据之后,还需要考虑怎么处理这些大批量的数据,从而找到有效的玩家反馈,在这方面,吕承通有自己的一套方法。
最关键的识别技术就是基于文本挖掘理论提炼出的一套算法,用这套算法来进行玩家的情感识别,确定出玩家对游戏的正面感情居多,还是负面感情居多,并从五个维度来分析玩家的感情程度,以-5~0~5来划分,只是目前由于1~5的等级划分程度还不够明确,所以体现到数据上的仅分为正面、负面和其他三种反馈。
除了情感识别之外,系统还会通过上下文语境关联的算法进行话题检测,计算出玩家话题聚焦的点在哪些地方,比如Bug、闪退、掉线、卡,等等。同时还会监控玩家讨论的话题集中在哪些游戏的哪些动态上,比如某个游戏的新系统或者新活动。
而为了保证这些数据的可靠性,ThinkingGame还在垃圾内容和无效内容上做了很完善识别机制。他们利用目前比较热门的深度学习技术,来让机器自动识别并过滤掉垃圾信息,比如贴吧的灌水帖、广告贴等等,系统误识别率在5%以内。
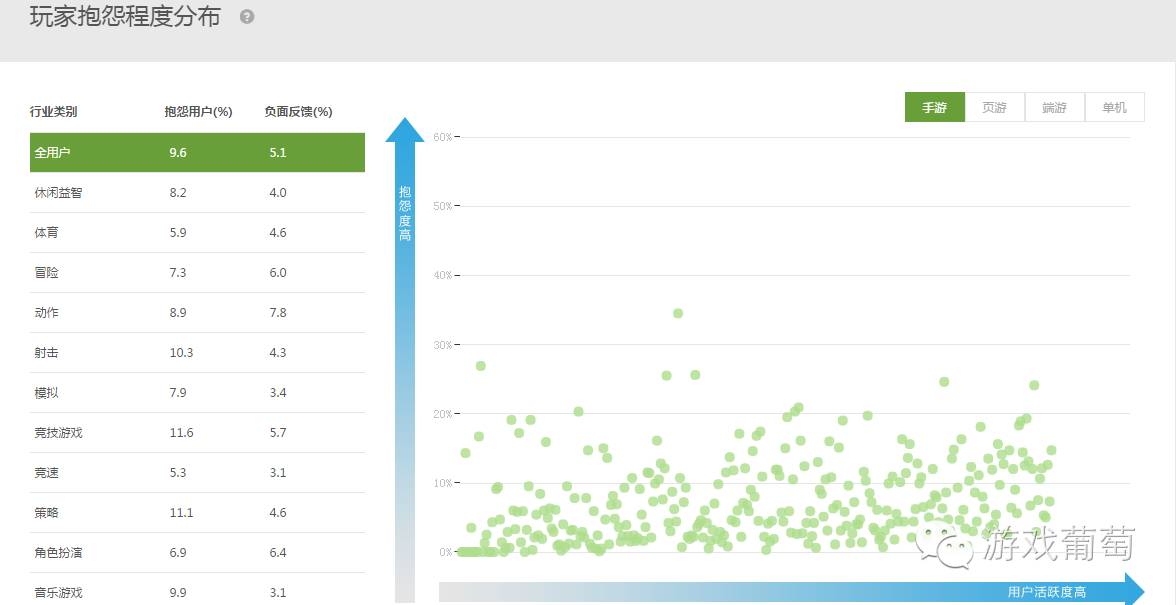
除了上面这些免费公开的服务内容,基于这些基础的技术,ThinkingGame还提供用户画像追踪、聊天记录分析等一些深度分析业务。
大数据是游戏的未来?
如今游戏行业普遍的数据处理工作,还处于一个非常繁琐的阶段(除了个别大厂),比如在成本有限的条件下,想要做深入直面核心玩家的反馈获取,往往不能做到特别大的规模。而在大范围的监控条件下,我们又很难做到实时了解玩家的动态,让一些可能发生的问题防患于未然,如果强行扩大监控范围,必然带来人力物力的消耗增加。
但是玩家每天除了登陆游戏、玩游戏,产生的大量感情和诉求,都不停的堆积在各个评论区和社区。葡萄君比较赞同吕承通的观点:“玩家产生的每个行为都是过去经历和思想堆积的结果”。通过收集玩家过去的所有信息,来有效地分析和判断他们接下来会产生的行为,并作出及时的应对和处理,带来的收益的确是有价值的,至少腾讯目前的成功就是最好的案例。